Hat Matrix In Ridge Regression

How To Calculate Hat Matrix For Penalized Spline Regressions Cross Validated
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf

Introduction To The Hat Matrix In Regression Youtube
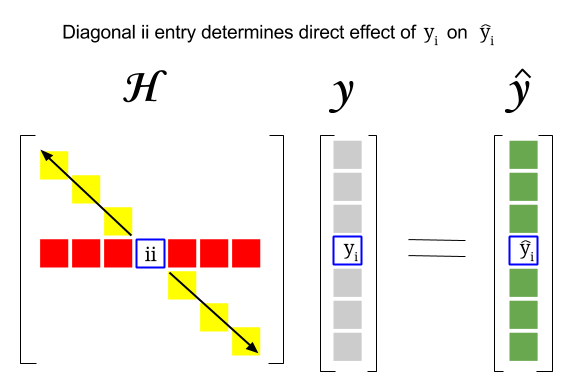
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Where H is the hat matrix.
Hat matrix in ridge regression. In statistics the projection matrix sometimes also called the influence matrix or hat matrix maps the vector of response values dependent variable values to the vector of fitted values or predicted values. I It is a good approximation I Because of the lack of training dataor smarter algorithms it is the most we can extract robustly from the data. Recall from ordinary regression that.
The degrees of freedom of ridge regression is calculated. In the OLS case we show that the residual is not orthogonal to X since Y λ is. Ridge regression - introduction.
As for ridge regression the Lasso is also formulated with respect to the centered matrixX here denotedXMoreover theL1-penalty is solely applied to the slope coecients and thus the intercept0 is excludedfrom the penalty term. As for ridge regression the Lasso can be expressed as aconstrained minimizationproblem. Standard least squares is scale-invariant but for penalized methods like ridge regression the scaling does matter in an important way because the coefficients are all put in a penalty term together.
In particular if X if of full rank ie. My understanding is that in ridge regression you add a penalty term which is equivalent to having a zero-centered normal prior on the parameters. In KR regression the input covariates are mapped to a high.
Ridge estimation is carried out on the linear regression model where. RankX p then. Is the vector of regression coefficients.
Thus far we have mainly be concerned with what may be called the variable space Rp in which each subject is a point and the variables are dimensions. Properties and Interpretation Week 5 Lecture 1 1 Hat Matrix 11 From Observed to Fitted Values. Y X y XX0X 1X0y y Hy H XX0X 1X0 so called the hat matrix because it transforms y to y The diagonal elements of the hat matrix the h is are proportional to the distance between X i from X i Hence h i is a simple measure of the leverage of Y i.
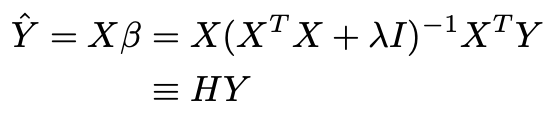
The Official Definition Of Degrees Of Freedom In Regression By Ravi Charan Towards Data Science
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf

Using The Hat Matrix To Detect Influential Observations In Logistic Regression Cross Validated

5 1 Ridge Regression Stat 897d
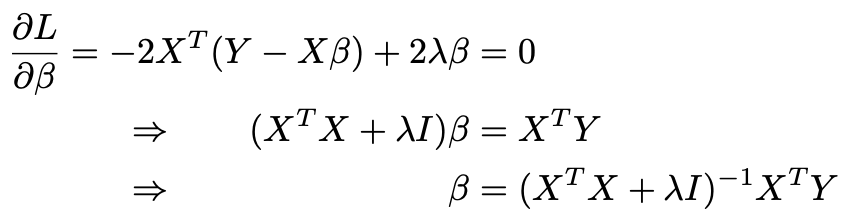
The Official Definition Of Degrees Of Freedom In Regression By Ravi Charan Towards Data Science

Side 2019 3

Linear Regression Chapter 9 Computational Statistics In The Earth Sciences

Kernel Ridge Regression A Toy Example Business Forecasting

Hat Matrix An Overview Sciencedirect Topics
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf
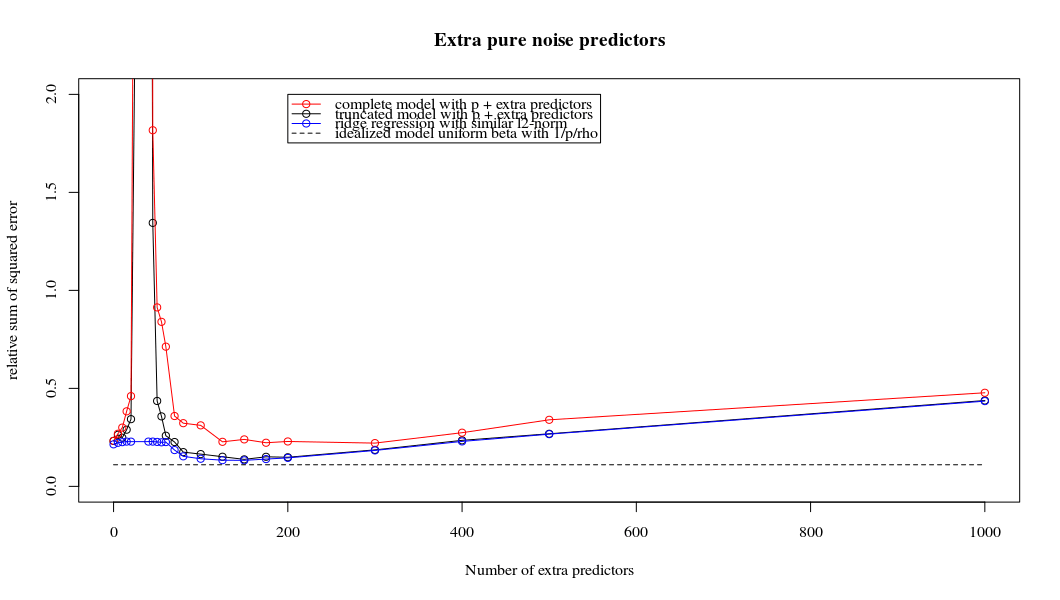
Is Ridge Regression Useless In High Dimensions N Ll P How Can Ols Fail To Overfit Cross Validated

4 1 Shrinkage Notes For Predictive Modeling
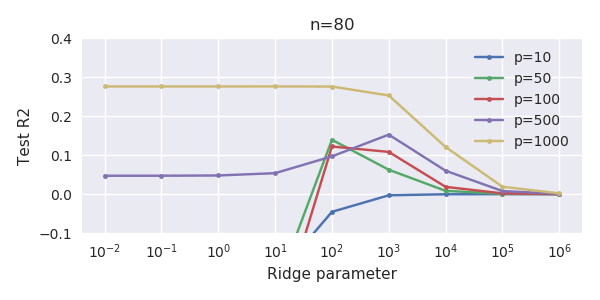
Is Ridge Regression Useless In High Dimensions N Ll P How Can Ols Fail To Overfit Cross Validated

