Hat Matrix In Regression In R

Introduction To The Hat Matrix In Regression Youtube

Notes For St463 St683 Linear Models 1

Residual Plot R Tutorial

Correlation And Regression With R

Run Multiple Regressions In For Loop In R Example Linear Models

Regression Analysis Ols Method
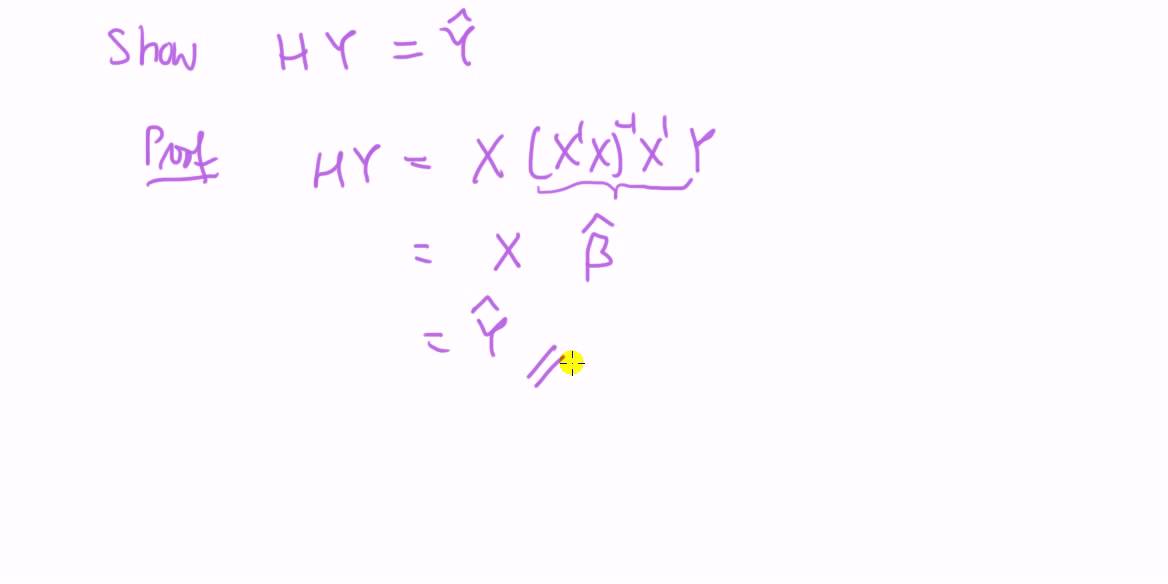
Multiple linear regression is expressed as below.
Hat matrix in regression in r. One important matrix that appears in many formulas is the so-called hat matrix H XXX-1X since it puts the hat on Y. The short story is that Stata estimates the hat matrix as H XXWX 1X while the usual approaches in R including sandwich and estimatr and Python eg. The invocation hatvalues vglmObject should return a n times M matrix of the diagonal elements of the hat projection matrix of a vglm object.
Lets look at some of the properties of the hat matrix. It is evident that the rightmost point is an outlier with very high hat value. Frank Wood fwoodstatcolumbiaedu Linear Regression Models Lecture 11 Slide 20 Hat Matrix Puts hat on Y We can also directly express the fitted values in terms of only the X and Y matrices and we can further define H the hat matrix The hat matrix plans an important role in diagnostics for regression analysis.
The hat matrix can be computed using formula X XXkI -1X equivalently λ_j λ_jk. If we only want the diagonal and trace of the hat matrix there is no need to do a matrix multiplication to first get the full hat matrix. To do this the QR decomposition of the object is retrieved or reconstructed and then straightforward calculations are performed.
Working paper Sloan School of Management. Example 1 continued First to evaluate the gradient matrix boldsymbolF_cdothatboldsymboltheta in the context of the first-order reaction model example we can make use of the deriv function which calculates exact symbolic derivatives for a number of common mathematical functions and compositions thereof. WELSCH In least-squares fitting it is important to understand the influence which a data y value will have on each fitted y value.
Where Y is the outcome with X as predictors. Details Hat matrix for scalar or vector values of biasing parameter provided as argument to lmridge. A projection matrix known as the hat matrix contains this information and together with the Studentized residuals provides a means of.
For linear models the trace of the hat matrix is equal to the rank of X which is the number of independent parameters of the linear model. Thus far we have mainly be concerned with what may be called the variable space Rp in which each subject is a point and the variables are dimensions. The deriv function returns an.

Notes For St463 St683 Linear Models 1

Regression Patterns Of Variation

Linear Algebra Behind The Lm Function In R Discovering Python R
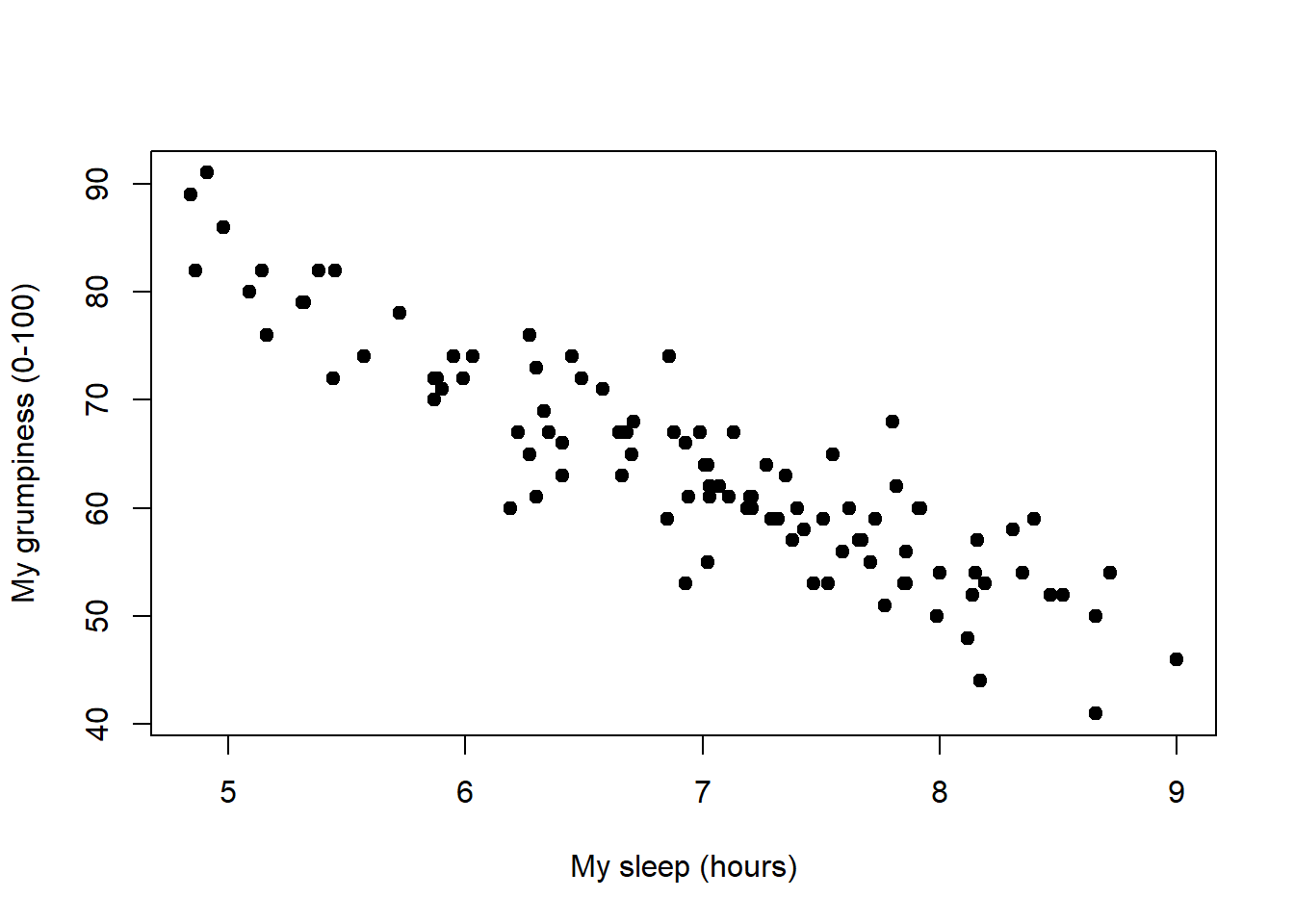
Learning Statistics With R A Tutorial For Psychology Students And Other Beginners Version 0 6 1

Correlation And Regression With R

Ch 1 Introduction To R Research Module In Econometrics Statistics

Inspiration And Help Concerning R Graphics Graphing Data Visualization Data Science
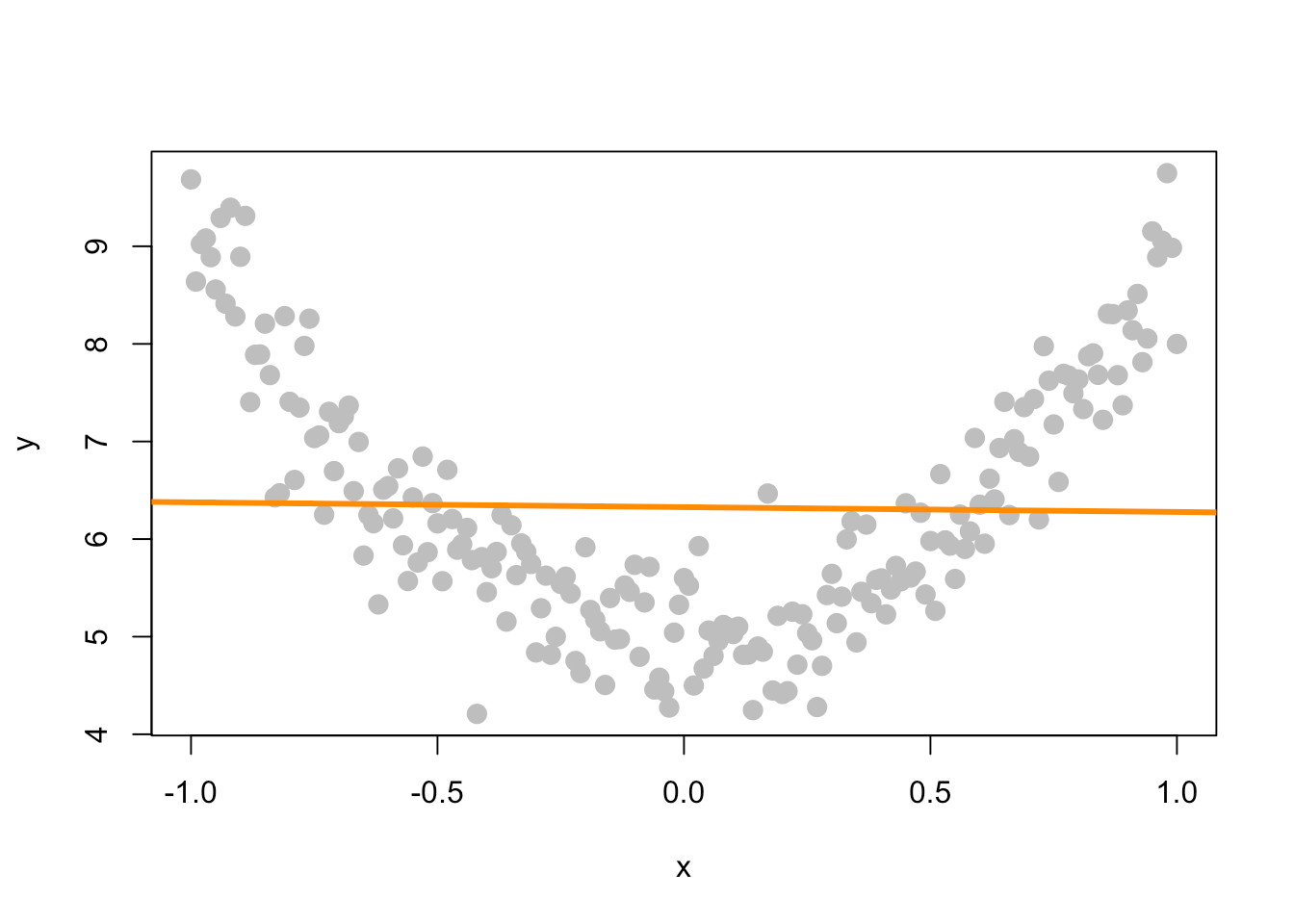
Chapter 8 Inference For Simple Linear Regression Applied Statistics With R
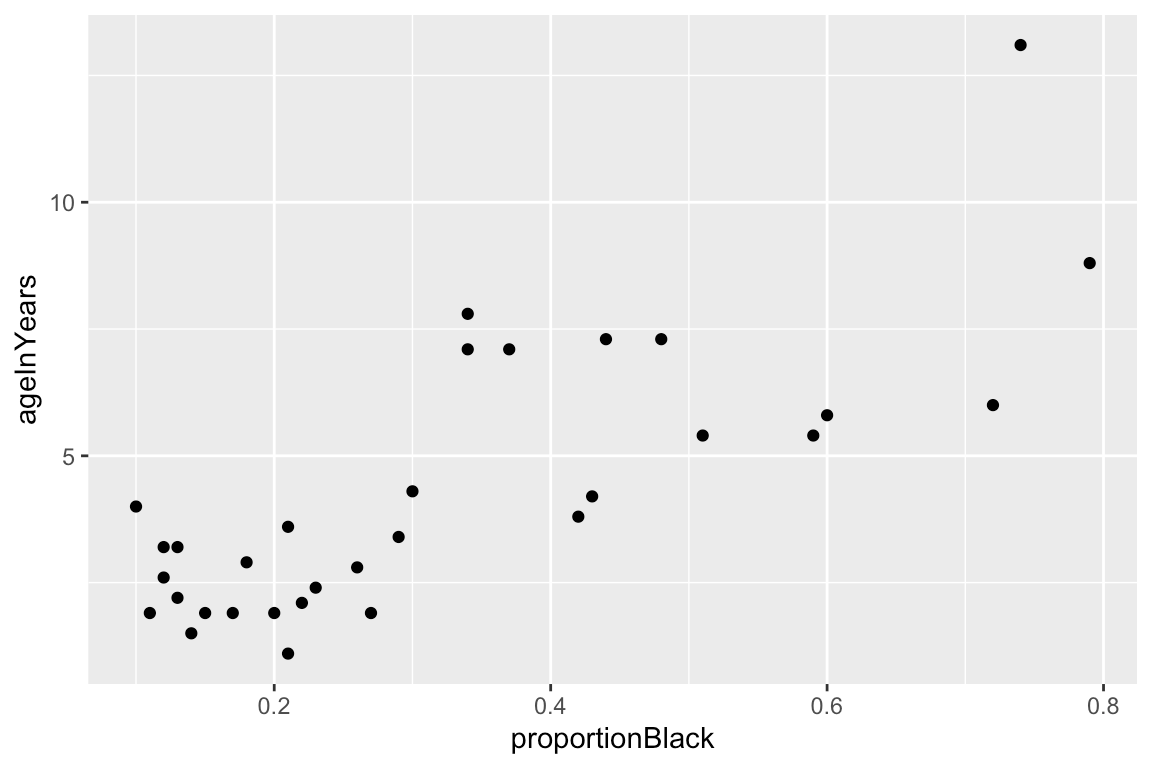
Chapter 12 Fitting Regression Models In R Biology 723 Statistical Computing For Biologists

1 Linkedin Equal Opportunity Teamwork Personal Growth

Going From R To Python Linear Regression Diagnostic Plots By Jason Sadowski Towards Data Science

8 Simple Steps To Implement Ols Regression Model In R By Anjita Agrawal Dataflair Medium

Lesson 9 Simple Linear Regression Basic Analytics In R

