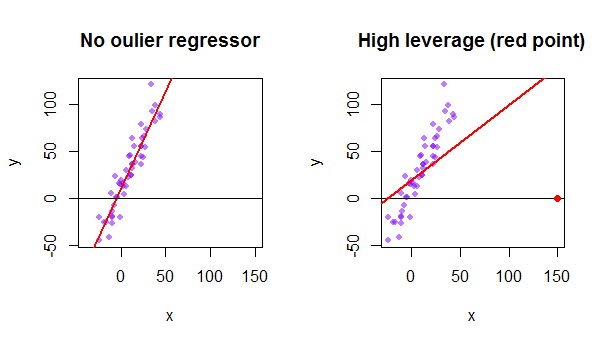
Hat Matrix Formula
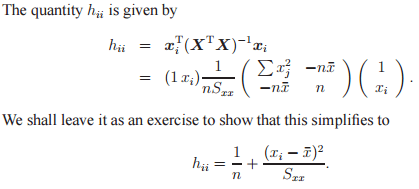
Hat Matrix With Simple Linear Regression Mathematics Stack Exchange

Introduction To The Hat Matrix In Regression Youtube
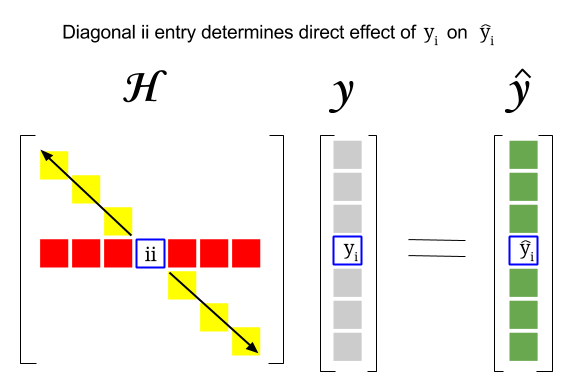
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

How To Calculate Hat Matrix For Penalized Spline Regressions Cross Validated

Properties Of Leverage Points In Regression With Proofs Note Typo Youtube
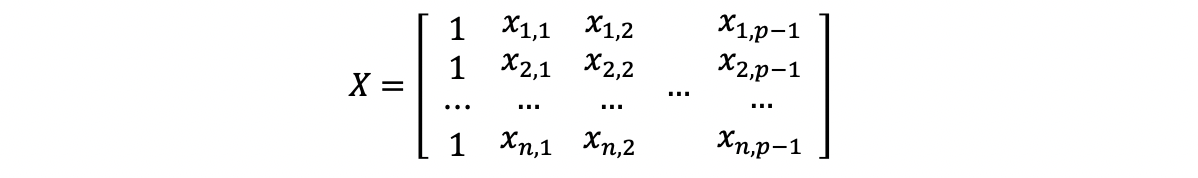
Linear Regression 5 Mlr Hat Matrix And Mlr Ols Evaluation By Adam Edelweiss Serenefield Medium
Der nachste Schritt ist das Ausmultiplizieren der Matrizen.
Hat matrix formula. The relationship between leverage and Mahalanobis distance enables us to decompose leverage into meaningful components so that some sources of high leverage can be investigated analytically. The hat matrix H is defined in terms of the data matrix X. This shows that the.
The predicted values ybcan then be written as by X b XXT X 1XT y. Diese Formel berechnet beispielsweise den Gesamtwert einer Matrix aus Aktienkursen und Anteilen und setzt das Ergebnis in die Zelle neben Gesamtwert. Der 1Eigenvektor ergibt sich aus folgender Gleichung.
Its usually called the hat matrix for obvious reasons or if we want to sound more respectable the in uence matrix. First I just manually calculated H using the definition of the hat matrix. The hat matrix H is defined in terms of the data matrix X.
Therefore the hat matrix is given by. Properties and Interpretation Week 5 Lecture 1 1 Hat Matrix 11 From Observed to Fitted Values The OLS estimator was found to be given by the p 1 vector b XT X 1XT y. Nun wollen wir die 3 Eigenvektoren der Matrix A bestimmen.
A B A 1 B. I am interested in calculating the hat matrix H for a linear regression model so that I can get the leverage values from the diagonal of H. λ 1 0.
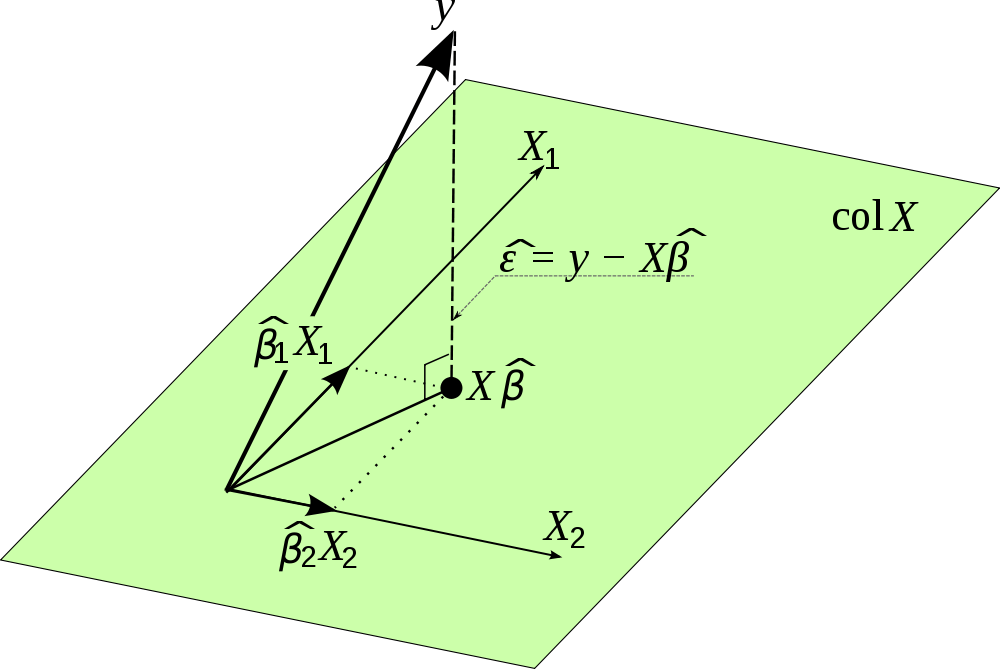
Lets look at some of the properties of the hat matrix. The regression residuals can be written in different ways as y yˆ y Xβˆ y Hy IHy 23. Math 261A - Spring 2012 M.
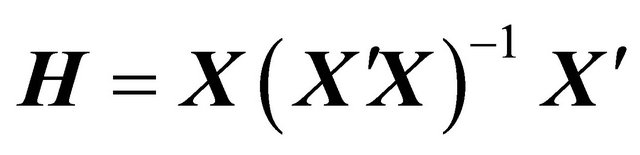
Detecting Global Influential Observations In Liu Regression Model

How Is It The Hat Matrix Spans The Column Space Of X Really Nice Youtube

For The Simple Linear Regression Model Show That The Chegg Com
What Is The Importance Of Hat Matrix H X X Top X 1 X Top In Linear Regression Cross Validated
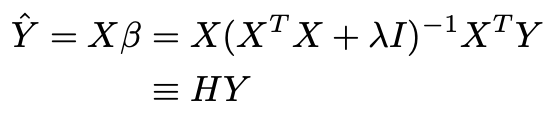
The Official Definition Of Degrees Of Freedom In Regression By Ravi Charan Towards Data Science

Multiple Linear Regression Matrix Formulation Let X X 1 X 2 X N Be A N 1 Column Vector And Let G X Be A Scalar Function Of X Then By Ppt Download
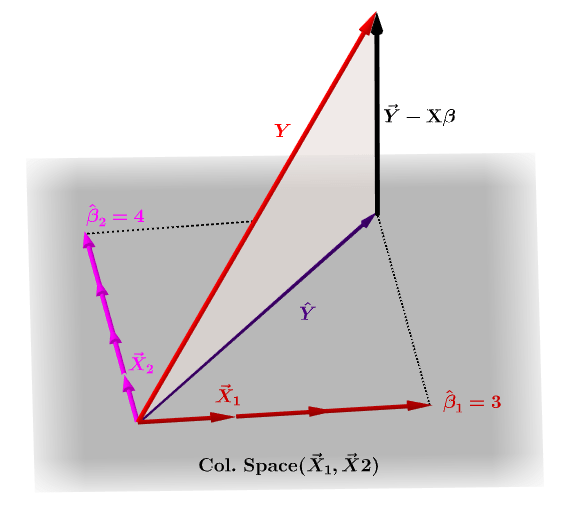
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

How To Derive Variance Covariance Matrix Of Coefficients In Linear Regression Cross Validated
Http Www Stat Columbia Edu Fwood Teaching W4315 Fall2009 Lecture 11

Hat Matrix An Overview Sciencedirect Topics

Linear Regression Using Matrix Multiplication In Python Using Numpy Python And R Tips
Http Www Stat Columbia Edu Fwood Teaching W4315 Fall2009 Lecture 11
Http Www Few Vu Nl Wvanwie Courses Highdimensionaldataanalysis Wnvanwieringen Hdda Lecture234 Ridgeregression 20182019 Pdf